.svg)




🔥 What’s New ?
👉 BigQuery: l’analyse de contribution est désormais accessible à tous
Pour les marketeurs, comprendre ce qui influence réellement les KPIs business est crucial. Prenons l'exemple d'une chaîne d'hôtels qui constate une augmentation de son panier moyen : est-ce dû à un changement de clientèle, à la performance d'un établissement particulier, ou à la popularité croissante de certaines catégories de chambres ? C'est exactement pour répondre à ces questions que BigQuery a lancé son nouveau modèle d'analyse de contribution, désormais accessible à tous les utilisateurs.
Cette analyse puissante permet d'identifier précisément les facteurs qui font évoluer les métriques, en comparant deux périodes ou segments de données. Le modèle utilise un jeu de données test et un jeu de contrôle pour isoler les véritables impacts.
Concrètement, ce modèle d'analyse de contribution utilise le machine learning et le traitement naturel du langage, ce qu'on appelle "l'analytics augmentée" pour détecter les segments de données qui montrent des changements significatifs dans une métrique, en comparant systématiquement les données à analyser avec un référentiel.
Dans notre exemple fictif d'une chaîne hôtelière française, cette analyse permet d'étudier l'évolution du panier moyen entre le Q4 2024 et le Q1 2025, en identifiant précisément les dimensions (type de chambre, localisation, nombre de personnes) qui ont le plus contribué à cette évolution.
Analysons les données de l'analyse de contribution imaginaire ( attention, les chiffres sont fictifs):
Globalement, nous avons une amélioration de 12,5% (différence de 150) entre les groupes test et contrôle.
Les facteurs clés à retenir :
- Réservations pour 2 participants : +30,8% (différence de 200), surperformance de 26,2%
- Suites vue piscine : Meilleure progression avec +36,4% (différence de 200)
- Aix-en-Provence : +19,5% (différence de 160)
- Hôtel "Les Lavandes Roses" : +12,2% (différence de 120), proche de la moyenne
Donc ce qu’on peut retenir de cette analyse c’est qu’il faut prioriser les actions sur les réservations pour deux personnes et les suites vue piscine qui montrent le plus fort potentiel.
{{bloc-notion-1}}
👉 Google Cloud Next 2025 : Un récap de ce qui s’est passé
{{bloc-notion-3}}
L'événement propose différentes sessions, ateliers et keynotes, animés par les équipes de Google, qui couvrent l'ensemble des produits Google Cloud.
Sans surprise, l'IA était au cœur de l'événement cette année, avec de nombreuses annonces majeures telles que :
- +TPUs Ironwood : La 7e génération de TPU Google, 10x plus puissante que la précédente.
- Agents IA : Disponibles via Google Agentspace pour tous les salariés des entreprises ayant Gemini dans le workspace Google pour rechercher, synthétiser et interagir avec les données.
- Gemini 2.5 Pro : En preview sur Vertex AI et l'app Gemini.
- Gemini 2.5 Flash : Version optimisée pour la latence et les coûts, bientôt sur Vertex AI et AI Studio.
- Lyria : Premier modèle “text to music” entreprise-ready qui génère des clips de 30 secondes.
- Suite d'engagement client : Solution CRM nouvelle génération pour créer des agents multi-canaux.
- Protocole A2A : Permet la communication entre agents IA, indépendamment de leur technologie.
- ADK : Framework open-source pour créer des agents IA en moins de 100 lignes de code.
- Gemini pour Google Workspace : Nouvelles fonctionnalités IA dans Docs, Sheets et Meet.
ℹ️ Plusieurs sessions sur tout ce qui est l’analyse de données ont eu lieu notamment par rapport à BigQuery, BigTable, Firestore, etc.Pour retrouver les replays des sessions, rendez-vous sur Google Cloud
{{bloc-notion-4}}
👉 Les agents IA dans BigQuery : Une transformation de la façon de gérer les pipelines de données
Lors d'une démo au Google Cloud Next 25, les équipes de BigQuery ont présenté une nouveauté qui pourrait changer notre manière de créer et gérer les pipelines de données, et ça concerne évidemment l'intégration de l'IA : les agents IA dans BigQuery.
Encore au stade expérimental, ces agents s'appuient sur l'IA pour rendre la création et la gestion de pipelines beaucoup plus simple et rapide.
Concrètement, ces agents sont capables d'analyser la manière dont les pipelines sont construits dans une organisation, d'en apprendre les modèles, et de s'en servir pour en créer de nouveaux ou adapter l’existant. En résumé, ces agents sont capables d'effectuer les tâches standards de préparation des données
Lors d’une démonstration menée par Terren Yim (BigQuery), plusieurs fonctionnalités ont été mises en avant :
- Créer un pipeline simplement en langage naturel : il suffit de décrire ce que l'on veut obtenir pour que l'agent construise le pipeline adapté. Par exemple, on peut demander à l’agent d’intégrer les données d’une table à une autre table en mentionnant la clé de jointure, l’agent analyzes the existing code, proposes modifications, and even highlights potential impacts on downstream processes.
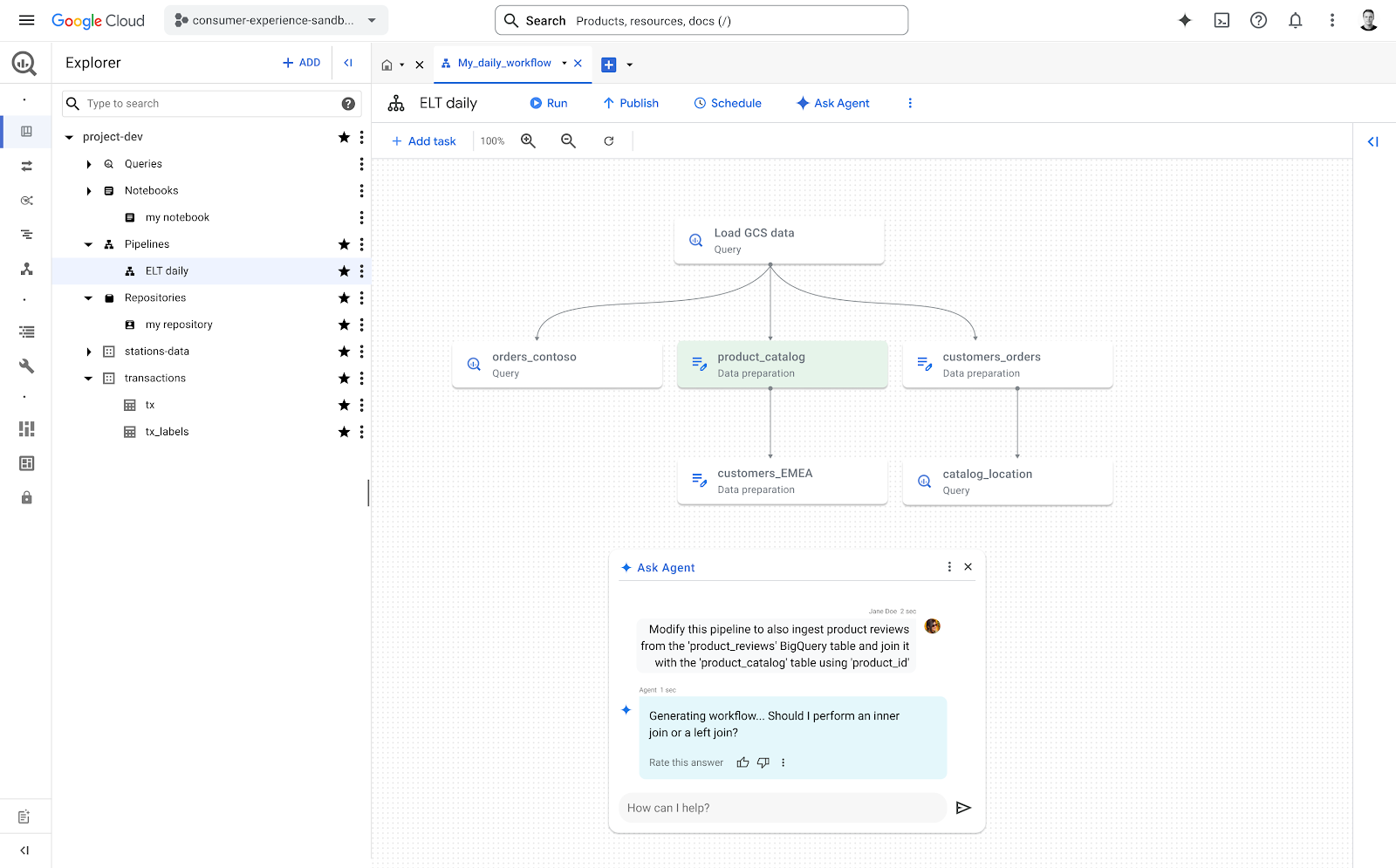
- Préparer les données intelligemment : nettoyage automatique des espaces blancs, normalisation et standardisation des valeurs... sans avoir besoin de tout préciser à la main.
- Modifier un pipeline de manière contextuelle : ajouter une jointure, découper un texte... tout se fait de façon conversationnelle.
- Travailler à grande échelle : possibilité de créer ou modifier plusieurs centaines de pipelines d'un seul coup via CLI ou API.
Le vrai potentiel de ces agents est le gain de temps car ils ont la capacité d’analyser un pipeline existant pour en extraire des modèles reproductibles. Cela permettra aux équipes de gagner un temps précieux, en créant rapidement de nouveaux pipelines alignés avec les standards internes.
ℹ️ Regardez la démo : Automatisez les pipelines de données avec des agents d'IA dans BigQuery
{{bloc-notion-5}}
Dans le cas ci-dessus, les Agents IA dans BigQuery vont nous aider à gagner du temps dans la partie la plus fastidieuse de la manipulation de données : le nettoyage, la standardisation et la documentation.
Ce qui donnera aux data engineers du temps pour exploiter d'autres typologies de données et travailler sur des sujets plus innovants, et aux data analysts, la possibilité d'analyser les patterns, comprendre les comportements, faire des analyses plus avancées, etc.
👉 Google Search Console : L'accès aux données horaires des 10 derniers jours est maintenant disponible via l'API
Alors que l'interface de Google Search Console affiche les données horaires uniquement pour les dernières 24 heures, l'API permet d'accéder aux données heure par heure sur une période allant jusqu'à 10 jours.
Les développeurs ou les ingénieurs de données peuvent ainsi créer des solutions qui montrent non seulement les données horaires du jour en cours, mais aussi établir des comparaisons avec le même jour de la semaine précédente, facilitant l'analyse des tendances hebdomadaires.
{{bloc-notion-2}}
👉 GA4 : Meilleure attribution du paid sur Google Ads et de nouveaux templates sur les rapports snapshots.
Des identifiants agrégés pour une meilleure attribution du trafic Google Ads :
Sur GA4, lorsque le GCLID ne peut pas être utilisé pour identifier les sources de trafic (par exemple quand les utilisateurs refusent le consentement ad_user_data), le trafic est attribué à l’organique. Désormais, Google va commencer à utiliser des identifiants agrégés pour attribuer le trafic payant aux différentes sources. Cette amélioration permet une attribution plus précise du trafic Google Ads, avec des annotations système pour signaler tout changement significatif.
De nouveaux modèles dans les rapports snapshot :
Les rapports snapshots sur GA4 proposent désormais de nouveaux modèles prédéfinis (Comportement utilisateur, Ventes et revenus, et Performance marketing), permettant aux utilisateurs d'obtenir rapidement une vue d'ensemble de leurs données.
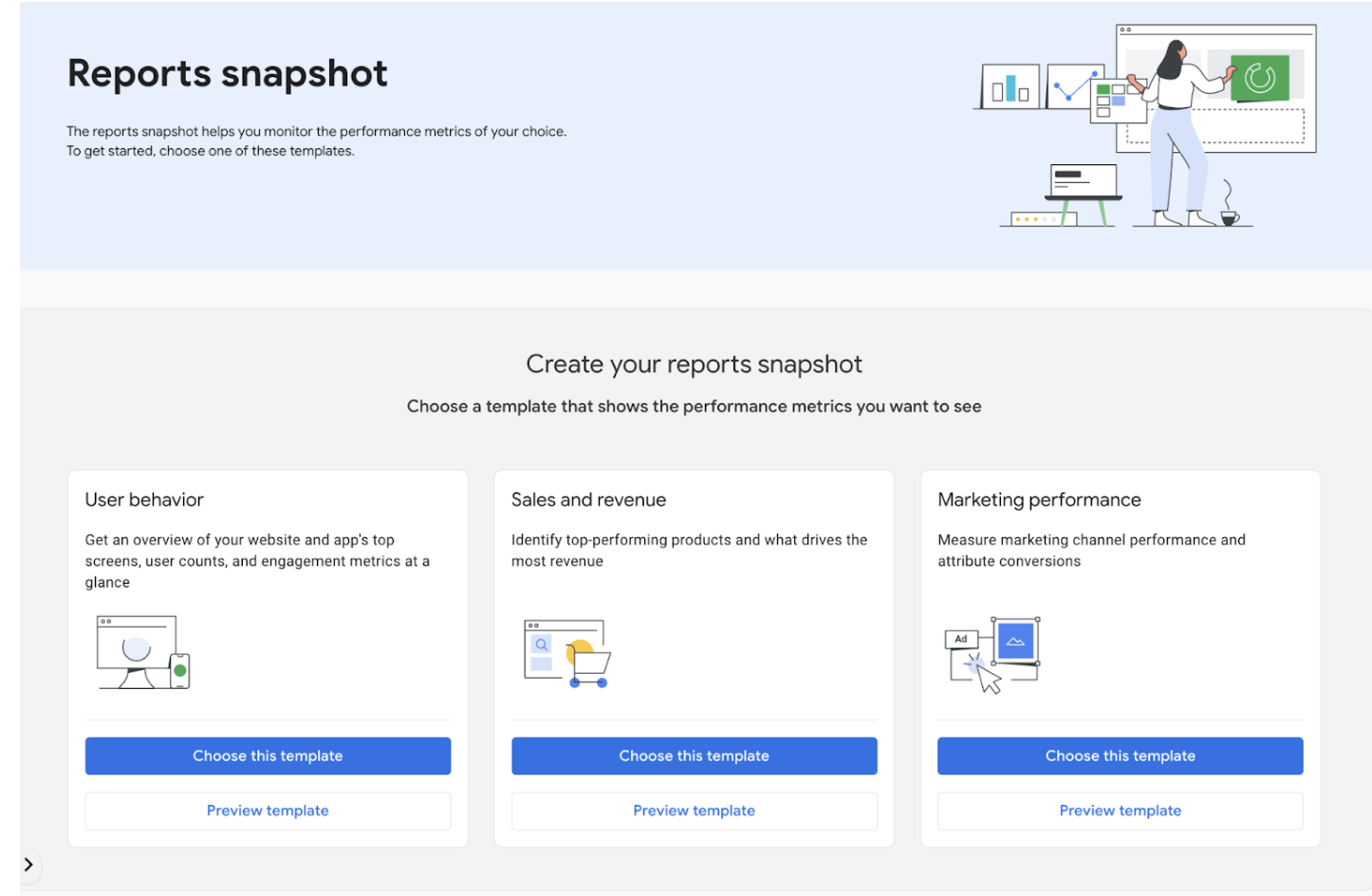
ℹ️ Découvrez plus d'infos sur Google Analytics
💡 L’astuce du mois
Notre rubrique "L'astuce du mois" partage des conseils pratiques utilisés quotidiennement chez Starfox Analytics. Ces astuces couvrent divers outils de Web Analyse pour optimiser votre travail. N'hésitez pas à les tester et à les partager avec vos collègues.
👉 Les résultats de requêtes mis en cache dans BigQuery
Chaque fois que BigQuery exécute une requête, il tente de mettre en cache son résultat (il existe certaines limitations). Si exactement la même requête est exécutée pendant que le cache est encore disponible (la durée de vie typique du cache est de 24 heures) — BigQuery récupérera les données depuis le cache et évitera de facturer à nouveau le traitement des données (bien sûr, uniquement si les données sous-jacentes n'ont pas changé entre les appels).
Donc, en résumé, tant que les données ne changent pas et que la requête est exactement la même, vous n'aurez besoin de payer que la première exécution. Et le meilleur dans tout ça, c'est que vous n'avez rien à faire pour que cela fonctionne car c'est le comportement par défaut.
💡 Pensez à partitionner et clusteriser vos tables afin d'optimiser vos requêtes et de contrôler vos coûts BigQuery. Le cache est un moyen par défaut d’optimisation, mais le partitionnement, le clustering, et toute optimisation de requête restent les leviers principaux pour maîtriser les coûts BigQuery.
📖 Sharing Is Caring
Notre rubrique "Sharing is Caring" présente mensuellement un article approfondi sur un sujet d'actualité en Web Analyse. Nos experts utilisent leur savoir-faire et les ressources en ligne pour explorer ces thématiques en détail.
Ce mois-ci, découvrez l'article de Oussama qui explique comment implémenter Matomo en server side sur GTM.
Déployer Matomo avec GTM server-Side
❤️ Meilleures ressources et articles du moment
- Une pépite de solutions open source de google marketing solutions avec les codes, la documentation, tout ce qu’on veut quoi sur Github !
- Un super article sur l’utilisation de Google Colab et Gemini pour faire de la Data Science . Découvrez les nouvelles news sur Google for Developers
- Un article complet sur l’Analytics Engineering Framework
- Un guide créé par MotherDuck pour mieux comprendre les différents types de logs auxquels un data ingénieur est confronté
🤩 Inside Starfox
🐞 Data Bugs
Chez Starfox, notre obsession pour le Lean se retrouve dans les moindres détails de notre organisation. Chaque bug n’est pas seulement corrigé : il est documenté, analysé et transformé en source d’apprentissage collectif. C’est tout le sens de notre log de bugs data, un outil structurant qui centralise les anomalies détectées, leur sévérité business, les délais de résolution, les causes racines et les environnements concernés.
Ce suivi rigoureux nous permet de calculer un score de "power" pour chaque bug, mais surtout de capitaliser sur nos erreurs pour accélérer la détection, réduire le lead time et éviter les incidents en production.
👉 Évidemment, on préfère toujours détecter une anomalie en phase de recette interne plutôt qu’en post-prod, signalée par le client
📍 Exemple #1 – GA4 : Chute du nombre d’utilisateurs
Une valeur par défaut user_id = "no_value" dans GTM a regroupé tous les utilisateurs non connectés sous un seul ID dans GA4, provoquant une forte sous-estimation des utilisateurs uniques.
✅ Suppression immédiate du fallback + mise en place de Trooper (notre outil de monitoring interne) pour éviter les dérives sur les clés de déduplication.
⏱️ Détecté en production par le client. Lead time entre détection et résolution : 4 heures. Temps total entre apparition du bug et sa résolution : 216 heures (9 jours).
📍 Exemple #2 – JS Error loop : Surcoût Addingwell
Un tag déclenchait en boucle un event error_event, générant 2,7M de hits GA4 en quelques heures.
✅ Tag désactivé + exclusion des erreurs JS côté server.
⏱️ Détecté en production par le client. Lead time entre détection et résolution : 2 heures. Temps total entre apparition du bug et sa résolution : 6 heures.
📍 Exemple #3 – GA4 vs Looker Studio : Métriques incohérentes
Des écarts venaient de l’usage de user_id (GA4) vs user_pseudo_id (BigQuery), créant une confusion dans le comptage des utilisateurs.
✅ Requête corrigée avec COALESCE(user_id, user_pseudo_id) + intégration dans nos templates standards.
⏱️ Détecté en préproduction par nos équipes internes. Lead time entre détection et résolution : 3 heures. Temps total entre apparition du bug et sa résolution : 8 heures.
🙌 Retour d’expérience client
Nous avons choisi d’investir dans des témoignages clients authentiques. Convaincus que la vidéo est un outil puissant pour raconter des histoires et créer du lien humain, nous avons décidé d’orienter notre communication dans ce sens, avec une priorité claire : privilégier la qualité à la quantité.
Voici le premier témoignage d’une série de quatre interventions que nous avons capturées avec soin. Chaque vidéo illustre non seulement nos résultats, mais aussi la richesse des collaborations qui font le succès de nos projets.

Un besoin, une question ?
Écrivez-nous à hello@starfox-analytics.com.
Notre équipe vous répondra au plus vite.






.svg)